I was watching a teardown video on one of the latest laptops and saw it using a relatively new memory format called LPCAMM2. That sent me down a rabbit hole to read up on it, and I thought I should share it with you.
To see why LPCAMM2 matters, we need to start with what laptops used earlier. For years, upgradeable laptops used SO-DIMM modules. Anyone who has opened up laptops in the last 10yrs would have seen this unit. A small pluggable RAM stick that you slide into a socket. It was cheap and easy to replace. But as memory speeds rose, SO-DIMM became problematic. The socket adds height, traces get longer, board area goes up, and you often need two modules to get full bandwidth.

That is why many thin laptops moved to soldered LPDDR. Putting memory much closer to the CPU shortens the path, improves the signal, and helps power and thickness. LPDDR also tends to use less power than standard DDR. The con is you lose RAM upgradeability and repairs are harder. Eg. Apple Laptops.
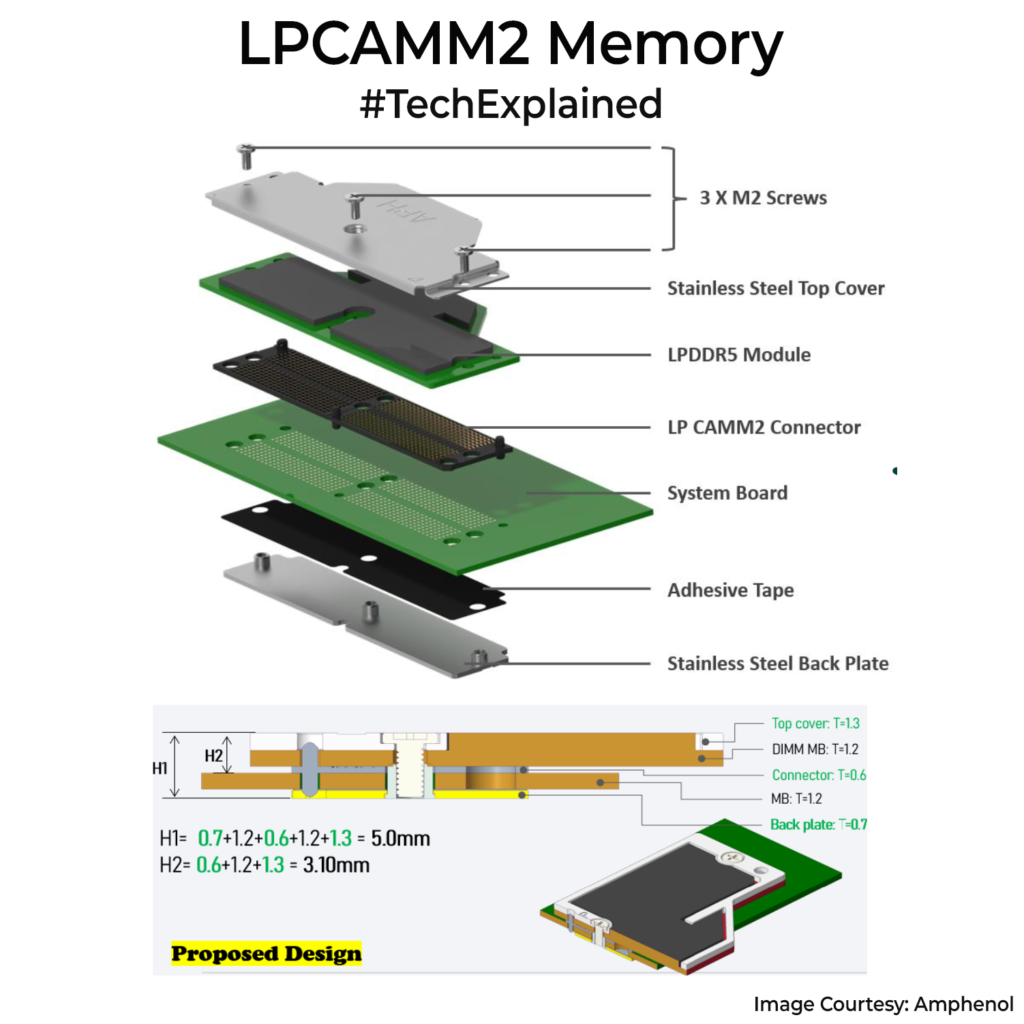
LPCAMM2 is the middle path. It uses LPDDR5X class memory, but keeps it on a replaceable module(Held on with 3 screws). The module lies almost flat and presses onto a compression connector with screws. This lowers height, saves space, and makes routing easier.

DDR5 SO-DIMM laptop memory has speed of around 5600 MT/s. LPCAMM2 modules are now showing 8533 MT/s to 9600 MT/s. That is a big jump with more data moved per second. One LPCAMM2 module can also expose a 128-bit interface, so one flat module can do the job that often needed two SO-DIMMs before.
Power is the other reason this matters. Because it is based on LPDDR5X, LPCAMM2 is designed for lower power operation than classic DDR5 SO-DIMM, especially in idle and standby. In a laptop, memory is always active in the background, so these savings matter.
I am really looking forward for this tech to take off in a big way. Hopefully regular consumer laptop OEMs switch to it soon. Not a fan of soldered RAM in devices anyway.
